Teknik Industri
Memahami Keputusan dengan Pohon Keputusan (Decision Tree)
Dipublikasikan oleh Sirattul Istid'raj pada 29 April 2025
Pohon keputusan atau Decision Tree adalah model hierarkis pendukung keputusan yang menggunakan struktur mirip pohon untuk menggambarkan keputusan dan konsekuensi-konsekuensinya, termasuk hasil-hasil dari kejadian kebetulan, biaya sumber daya, dan utilitas. Ini merupakan salah satu cara untuk menampilkan algoritma yang hanya mengandung pernyataan kontrol kondisional.
Pohon keputusan umumnya digunakan dalam riset operasi, khususnya dalam analisis keputusan, untuk membantu mengidentifikasi strategi yang paling mungkin mencapai tujuan, tetapi juga merupakan alat yang populer dalam pembelajaran mesin.
Pohon keputusan adalah struktur mirip bagan alir di mana setiap simpul internal mewakili "tes" pada atribut (misalnya, apakah lemparan koin muncul kepala atau ekor), setiap cabang mewakili hasil dari tes tersebut, dan setiap simpul daun mewakili label kelas (keputusan yang diambil setelah menghitung semua atribut). Jalur dari akar ke daun mewakili aturan klasifikasi.
Dalam analisis keputusan, pohon keputusan dan diagram pengaruh yang terkait erat digunakan sebagai alat bantu keputusan visual dan analitis, di mana nilai-nilai yang diharapkan (atau utilitas yang diharapkan) dari alternatif-alternatif yang bersaing dihitung.
Sebuah pohon keputusan terdiri dari tiga jenis simpul:
- Simpul keputusan – biasanya direpresentasikan oleh kotak
- Simpul kebetulan – biasanya direpresentasikan oleh lingkaran
- Simpul akhir – biasanya direpresentasikan oleh segitiga
Pohon keputusan umumnya digunakan dalam riset operasi dan manajemen operasi. Jika, dalam praktiknya, keputusan harus diambil secara online tanpa pengingat di bawah pengetahuan yang tidak lengkap, sebuah pohon keputusan harus diparalelkan dengan model probabilitas sebagai model pilihan terbaik atau algoritma pemilihan online. Penggunaan lain dari pohon keputusan adalah sebagai sarana deskriptif untuk menghitung probabilitas bersyarat.
Pohon keputusan, diagram pengaruh, fungsi utilitas, dan alat dan metode analisis keputusan lainnya diajarkan kepada mahasiswa sarjana di sekolah-sekolah bisnis, ekonomi kesehatan, dan kesehatan masyarakat, dan merupakan contoh dari metode riset operasi atau ilmu manajemen.
Blok-blok pembangun pohon keputusan (Decision-tree elements)
Elemen pohon keputusan
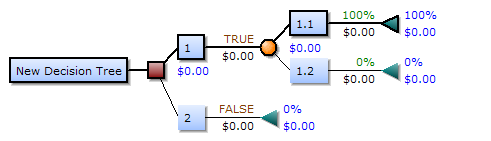
Jika digambar dari kiri ke kanan, sebuah pohon keputusan hanya memiliki simpul-simpul pecah (jalur pembelahan) tetapi tidak memiliki simpul-simpul penyatu (jalur konvergen). Oleh karena itu, jika digunakan secara manual, pohon keputusan dapat menjadi sangat besar dan seringkali sulit untuk digambar sepenuhnya dengan tangan. Secara tradisional, pohon keputusan dibuat secara manual - seperti yang ditunjukkan pada contoh di samping - meskipun semakin banyak digunakan software khusus.
Aturan keputusan (Decision rules)
Pohon keputusan dapat di linearisasikan menjadi aturan keputusan, di mana hasilnya adalah isi dari simpul daun, dan kondisi-kondisi sepanjang jalur membentuk konjungsi dalam klausa if. Secara umum, aturan-aturan tersebut memiliki bentuk:
jika kondisi1 dan kondisi2 dan kondisi3 maka hasilnya. Aturan keputusan dapat dihasilkan dengan membangun aturan asosiasi dengan variabel target di sebelah kanan. Mereka juga dapat menunjukkan hubungan temporal atau kausal.
Pohon keputusan menggunakan flowchart simbol
Biasanya pohon keputusan digambarkan menggunakan simbol-simbol bagan alir karena lebih mudah bagi banyak orang untuk dibaca dan dipahami. Perlu diperhatikan bahwa terdapat kesalahan konseptual dalam perhitungan "Lanjut" dari pohon yang ditunjukkan di bawah ini; kesalahan tersebut terkait dengan perhitungan "biaya" yang diberikan dalam tindakan hukum.
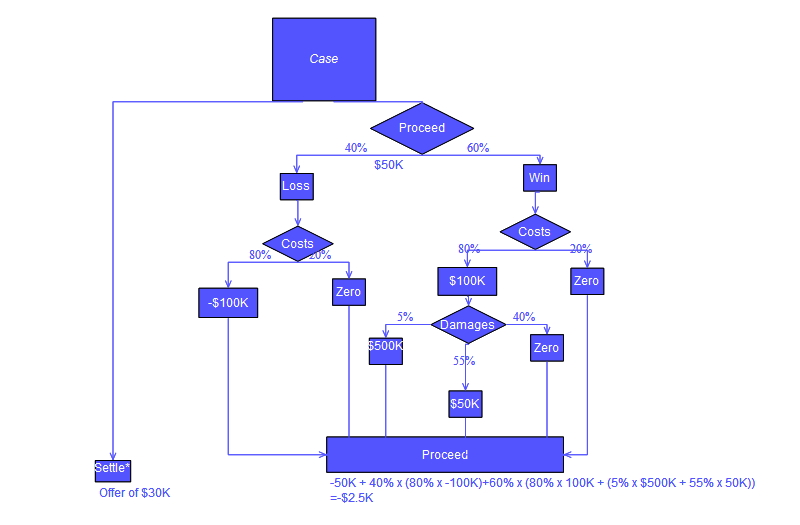
Contoh Analisis
Analisis dapat memperhitungkan preferensi atau fungsi utilitas pengambil keputusan (misalnya, perusahaan), sebagai contoh:
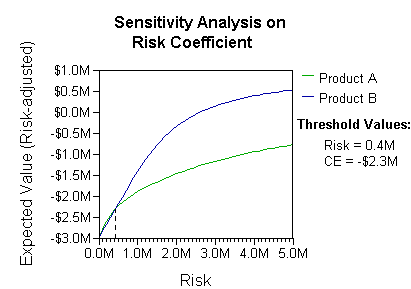
Interpretasi dasar dalam situasi ini adalah bahwa perusahaan lebih memilih risiko dan imbalan dari B dengan koefisien preferensi risiko yang realistis (lebih besar dari $400 ribu - dalam rentang kecenderungan risiko tersebut, perusahaan akan perlu memodelkan strategi ketiga, "Tidak A maupun B").
Contoh lain yang umum digunakan dalam kursus riset operasi adalah distribusi penjaga pantai di pantai-pantai (dikenal sebagai contoh "Life's a Beach"). Contoh tersebut menggambarkan dua pantai dengan penjaga pantai yang akan didistribusikan di setiap pantai. Ada anggaran maksimum B yang dapat didistribusikan di antara kedua pantai (secara total), dan dengan menggunakan tabel pengembalian marjinal, para analis dapat memutuskan berapa banyak penjaga pantai yang dialokasikan ke masing-masing pantai.
Diagram pengaruh (Influence diagram)
Sebagian besar informasi dalam sebuah pohon keputusan dapat direpresentasikan lebih ringkas sebagai diagram pengaruh, yang memfokuskan perhatian pada masalah-masalah dan hubungan antara peristiwa-peristiwa.
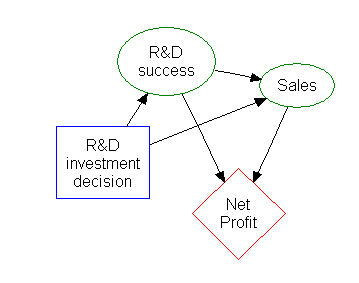
Induksi Aturan Asosiasi
Pohon keputusan juga dapat dilihat sebagai model generatif dari aturan induksi dari data empiris. Sebuah pohon keputusan optimal kemudian didefinisikan sebagai pohon yang memperhitungkan sebagian besar data, sambil meminimalkan jumlah level (atau "pertanyaan"). Beberapa algoritma untuk menghasilkan pohon-pohon optimal tersebut telah dikembangkan, seperti ID3/4/5, CLS, ASSISTANT, dan CART.
Kelebihan dan Kekurangan
Di antara alat bantu keputusan, pohon keputusan (dan diagram pengaruh) memiliki beberapa keunggulan. Pohon keputusan:
- Mudah dipahami dan diinterpretasikan. Orang dapat memahami model pohon keputusan setelah penjelasan singkat.
- Memiliki nilai bahkan dengan sedikit data keras. Insight penting dapat dihasilkan berdasarkan ahli yang menggambarkan situasi (alternatifnya, probabilitas, dan biaya), serta preferensi mereka terhadap hasil.
- Membantu menentukan nilai terburuk, terbaik, dan yang diharapkan untuk berbagai skenario.
- Menggunakan model kotak putih. Jika hasil tertentu diberikan oleh sebuah model.
- Dapat digabungkan dengan teknik keputusan lainnya.
- Tindakan dari lebih dari satu pengambil keputusan dapat dipertimbangkan.
Kekurangan dari pohon keputusan:
- Tidak stabil, yang berarti perubahan kecil dalam data dapat menyebabkan perubahan besar dalam struktur pohon keputusan optimal.
- Seringkali relatif tidak akurat. Banyak prediktor lain memiliki kinerja yang lebih baik dengan data serupa. Hal ini dapat diperbaiki dengan menggantikan satu pohon keputusan dengan hutan acak dari pohon keputusan, tetapi hutan acak tidak sesederhana pohon keputusan tunggal dalam interpretasinya.
- Untuk data yang mencakup variabel kategoris dengan jumlah level yang berbeda, peningkatan informasi dalam pohon keputusan bias dalam mendukung atribut-atribut dengan lebih banyak level.
- Perhitungan dapat menjadi sangat kompleks, terutama jika banyak nilai tidak pasti dan/atau jika banyak hasil terkait.
Optimisasi Pohon Keputusan
Beberapa hal harus dipertimbangkan saat meningkatkan akurasi klasifikasi pohon keputusan. Berikut adalah beberapa optimisasi yang mungkin perlu dipertimbangkan untuk memastikan model pohon keputusan yang dihasilkan membuat keputusan atau klasifikasi yang benar. Perlu dicatat bahwa hal-hal ini bukanlah satu-satunya hal yang perlu dipertimbangkan, tetapi hanya beberapa di antaranya.
Meningkatkan jumlah level pohon
Akurasi pohon keputusan dapat berubah berdasarkan kedalaman pohon keputusan. Dalam banyak kasus, daun pohon adalah simpul murni. Ketika sebuah simpul adalah murni, berarti semua data dalam simpul tersebut termasuk dalam satu kelas. Sebagai contoh, jika kelas-kelas dalam kumpulan data adalah Kanker dan Non-Kanker, sebuah simpul daun akan dianggap murni ketika semua data sampel dalam simpul daun tersebut merupakan bagian dari satu kelas saja, baik kanker atau non-kanker. Perlu diingat bahwa pohon yang lebih dalam tidak selalu lebih baik saat mengoptimalkan pohon keputusan. Pohon yang lebih dalam dapat mempengaruhi waktu eksekusi secara negatif. Jika sebuah algoritma klasifikasi tertentu digunakan, maka pohon yang lebih dalam dapat berarti waktu eksekusi algoritma klasifikasi ini secara signifikan lebih lambat. Ada juga kemungkinan bahwa algoritma yang sebenarnya membangun pohon keputusan akan menjadi lebih lambat secara signifikan seiring dengan kedalaman pohon yang meningkat. Jika algoritma pembangunan pohon yang digunakan membagi simpul murni, maka dapat mengalami penurunan akurasi keseluruhan dari klasifikasi pohon. Kadang-kadang, peningkatan kedalaman pohon dapat menyebabkan penurunan akurasi secara umum, sehingga sangat penting untuk menguji modifikasi kedalaman pohon keputusan dan memilih kedalaman yang menghasilkan hasil terbaik. Untuk merangkum, perhatikan poin-poin di bawah ini, kita akan mendefinisikan jumlah D sebagai kedalaman pohon.
Keuntungan kemungkinan dari peningkatan jumlah D:
- Akurasi model klasifikasi pohon keputusan meningkat.
- Kemungkinan kerugian dari peningkatan D:
- Masalah waktu eksekusi
- Penurunan akurasi secara umum
- Pembagian simpul murni saat semakin dalam bisa menyebabkan masalah.
- Kemampuan untuk menguji perbedaan hasil klasifikasi ketika mengubah D sangat penting. Kita harus dapat dengan mudah mengubah dan menguji variabel-variabel yang dapat memengaruhi akurasi dan keandalan model pohon keputusan.
Pemilihan fungsi pembagian simpul
Fungsi pembagian simpul yang digunakan dapat berdampak pada peningkatan akurasi pohon keputusan. Sebagai contoh, menggunakan fungsi gain informasi mungkin menghasilkan hasil yang lebih baik daripada menggunakan fungsi phi. Fungsi phi dikenal sebagai ukuran "kebaikan" dari pemisahan kandidat di simpul dalam pohon keputusan. Fungsi gain informasi dikenal sebagai ukuran "pengurangan entropi". Pada contoh berikut, kita akan membangun dua pohon keputusan. Satu pohon keputusan akan dibangun menggunakan fungsi phi untuk membagi simpul-simpul dan satu pohon keputusan akan dibangun menggunakan fungsi gain informasi untuk membagi simpul-simpul.
Kelebihan dan kekurangan utama dari gain informasi dan fungsi phi
Salah satu kelemahan utama dari gain informasi adalah bahwa fitur yang dipilih sebagai simpul berikutnya dalam pohon cenderung memiliki nilai unik yang lebih banyak. Keuntungan dari gain informasi adalah cenderung memilih fitur yang paling berdampak yang berada dekat dengan akar pohon. Ini adalah ukuran yang sangat baik untuk memutuskan relevansi beberapa fitur. Fungsi phi juga merupakan ukuran yang baik untuk memutuskan relevansi beberapa fitur berdasarkan "kebaikan". Ini adalah formula fungsi gain informasi. Rumus ini menyatakan bahwa gain informasi adalah fungsi dari entropi sebuah simpul pohon keputusan dikurangi entropi pemisahan kandidat di simpul t dari sebuah pohon keputusan.

Ini adalah rumus fungsi phi. Fungsi phi dimaksimalkan ketika fitur yang dipilih membagi sampel sedemikian rupa sehingga menghasilkan pemisahan yang homogen dan memiliki jumlah sampel yang kurang lebih sama di setiap pemisahan.

Kita akan menetapkan D, yang merupakan kedalaman pohon pilihan yang sedang kita bangun, menjadi tiga (D = 3). Kita juga memiliki kumpulan informasi yang diambil dari tes kanker dan non-kanker dan transformasi menyoroti bahwa tes tersebut memiliki atau tidak memiliki. Jika sebuah tes mencakup perubahan yang disertakan pada saat itu, maka tes tersebut positif terhadap perubahan tersebut, dan akan disebut sebagai tes. Jika suatu tes tidak memiliki perubahan include pada saat itu, maka tes tersebut negatif untuk perubahan tersebut, dan akan disebut dengan nol.
Evaluasi Pohon Keputusan (Decision Tree)
Penting untuk mengetahui pengukuran yang digunakan untuk mengevaluasi pohon keputusan. Metrik utama yang digunakan adalah akurasi, sensitivitas, spesifisitas, presisi, tingkat kesalahan prediksi negatif, tingkat kesalahan prediksi positif, dan tingkat pengabaian prediksi negatif. Semua pengukuran ini berasal dari jumlah positif benar, positif palsu, negatif benar, dan negatif palsu yang diperoleh saat menjalankan serangkaian sampel melalui model klasifikasi pohon keputusan. Selain itu, sebuah matriks kebingungan dapat dibuat untuk menampilkan hasil-hasil ini. Semua metrik utama ini memberikan informasi yang berbeda tentang kelebihan dan kelemahan model klasifikasi yang dibangun berdasarkan pohon keputusan Anda. Sebagai contoh, sensitivitas yang rendah dengan spesifisitas yang tinggi bisa menunjukkan bahwa model klasifikasi yang dibangun dari pohon keputusan tidak baik dalam mengidentifikasi sampel kanker dibandingkan dengan sampel non-kanker.
Disadur dari: en.wikipedia.org

Teknik Industri
Pemahaman Mendalam tentang Mesin Pendukung Vektor (SVM) dalam Pembelajaran Mesin
Dipublikasikan oleh Sirattul Istid'raj pada 29 April 2025
Mesin Pendukung Vektor (SVM) atau juga dikenal sebagai jaringan pendukung vektor, merupakan model-model terarah berbasis margin maksimum yang menggunakan algoritma pembelajaran terkait untuk menganalisis data dalam klasifikasi dan analisis regresi. Dikembangkan di Laboratorium Bell AT&T oleh Vladimir Vapnik bersama rekan-rekannya, SVM menjadi salah satu model yang paling banyak dipelajari, didasarkan pada kerangka pembelajaran statistik atau teori VC yang diusulkan oleh Vapnik dan Chervonenkis.
Selain melakukan klasifikasi linear, SVM dapat secara efisien melakukan klasifikasi non-linear menggunakan apa yang disebut trik kernel, dengan secara implisit memetakan inputnya ke dalam ruang fitur berdimensi tinggi. SVM juga dapat digunakan untuk tugas regresi, di mana tujuannya adalah menjadi 
Algoritma pengelompokan vektor pendukung, yang dibuat oleh Hava Siegelmann dan Vladimir Vapnik, menerapkan statistik vektor pendukung yang dikembangkan dalam algoritma mesin pendukung vektor untuk mengategorikan data tanpa label. Dataset ini memerlukan pendekatan pembelajaran tanpa pengawasan, yang mencoba untuk menemukan pengelompokan alami dari data ke dalam kelompok-kelompok, dan kemudian memetakan data baru sesuai dengan kelompok-kelompok ini.
Populeritas SVM mungkin disebabkan oleh kemampuannya untuk analisis teoritis, fleksibilitasnya dalam diterapkan pada berbagai macam tugas, termasuk masalah prediksi terstruktur. Namun, belum jelas apakah SVM memiliki kinerja prediksi yang lebih baik daripada model linear lainnya, seperti regresi logistik dan regresi linear.
Motivasi
Klasifikasi data adalah tugas umum dalam pembelajaran mesin. Anggaplah beberapa titik data yang diberikan masing-masing termasuk ke dalam salah satu dari dua kelas, dan tujuannya adalah untuk menentukan kelas mana titik data baru akan berada. Dalam kasus mesin pendukung vektor, sebuah titik data dilihat sebagai vektor berdimensi-p (sebuah daftar dari p angka), dan kita ingin tahu apakah kita dapat memisahkan titik-titik tersebut dengan sebuah hiperplan berdimensi-(p-1). Ini disebut sebagai klasifikasi linear. Ada banyak hiperplan yang dapat mengklasifikasikan data. Salah satu pilihan yang masuk akal sebagai hiperplan terbaik adalah yang mewakili pemisahan terbesar, atau margin, antara dua kelas. Jadi kita memilih hiperplan sehingga jarak dari hiperplan tersebut ke titik data terdekat di setiap sisi maksimum. Jika hiperplan semacam itu ada, dikenal sebagai hiperplan margin maksimum dan klasifikasi linear yang didefinisikan olehnya dikenal sebagai klasifikasi margin maksimum; atau setara, perceptron kestabilan optimal.
Secara lebih formal, sebuah mesin pendukung vektor membangun sebuah hiperplan atau serangkaian hiperplan dalam ruang berdimensi tinggi atau tak terbatas, yang dapat digunakan untuk klasifikasi, regresi, atau tugas lain seperti deteksi outliers. Secara intuitif, pemisahan yang baik dicapai oleh hiperplan yang memiliki jarak terbesar ke titik data pelatihan terdekat dari setiap kelas (yang disebut margin fungsional), karena pada umumnya semakin besar margin, semakin rendah kesalahan generalisasi klasifier. Kesalahan generalisasi yang lebih rendah berarti bahwa pengimplementasi kurang mungkin mengalami overfitting.
Sementara masalah asli mungkin dinyatakan dalam ruang berdimensi terbatas, sering kali terjadi bahwa set yang akan dipisahkan tidak dapat dipisahkan secara linear dalam ruang tersebut. Oleh karena itu, diusulkan bahwa ruang berdimensi terbatas asli tersebut dipetakan ke dalam ruang berdimensi yang jauh lebih tinggi, dengan harapan membuat pemisahan lebih mudah dalam ruang tersebut. Untuk menjaga beban komputasi yang wajar, pemetaan yang digunakan oleh skema SVM dirancang untuk memastikan bahwa perkalian dot dari pasangan vektor data input dapat dengan mudah dihitung dalam hal variabel-variabel dalam ruang asli, dengan mendefinisikan mereka dalam hal sebuah fungsi kernel k(x, y) yang dipilih sesuai dengan masalah. Hiperplan dalam ruang berdimensi tinggi tersebut didefinisikan sebagai set titik-titik yang perkalian dot-nya dengan sebuah vektor di ruang tersebut konstan, di mana sebuah set vektor tersebut adalah set vektor ortogonal (dan oleh karena itu minimal) yang mendefinisikan sebuah hiperplan. Vektor-vektor yang mendefinisikan hiperplan dapat dipilih sebagai kombinasi linear dengan parameter ai dari gambar vektor fitur 

Aplikasi Algoritma SVM
SVM dapat digunakan untuk menyelesaikan berbagai masalah dunia nyata:
-
SVM membantu dalam kategorisasi teks dan hiperteks, karena aplikasinya dapat secara signifikan mengurangi kebutuhan akan contoh pelatihan yang diberi label dalam kedua pengaturan induktif dan transduktif. Beberapa metode untuk parsing semantik dangkal didasarkan pada mesin pendukung vektor.
-
Klasifikasi gambar juga dapat dilakukan menggunakan SVM. Hasil eksperimental menunjukkan bahwa SVM mencapai akurasi pencarian yang jauh lebih tinggi daripada skema penyempurnaan kueri tradisional setelah hanya tiga hingga empat putaran umpan balik relevansi. Hal ini juga berlaku untuk sistem segmentasi gambar, termasuk yang menggunakan versi SVM yang dimodifikasi dengan pendekatan istimewa seperti yang disarankan oleh Vapnik.
-
Klasifikasi data satelit seperti data SAR menggunakan SVM yang diawasi.
-
Karakter tulisan tangan dapat dikenali menggunakan SVM.
-
Algoritma SVM telah banyak diterapkan dalam bidang biologi dan ilmu lainnya. Mereka telah digunakan untuk mengklasifikasikan protein dengan hingga 90% senyawa diklasifikasikan dengan benar. Uji permutasi berdasarkan bobot SVM telah disarankan sebagai mekanisme untuk interpretasi model SVM. Bobot mesin pendukung vektor juga telah digunakan untuk menginterpretasikan model SVM di masa lalu. Interpretasi pasca hoc dari model mesin pendukung vektor untuk mengidentifikasi fitur-fitur yang digunakan oleh model untuk membuat prediksi adalah area penelitian yang relatif baru namun memiliki signifikansi khusus dalam ilmu biologi.
Sejarah Algoritma SVM
Algoritma SVM asli ditemukan oleh Vladimir N. Vapnik dan Alexey Ya. Chervonenkis pada tahun 1964. Pada tahun 1992, Bernhard Boser, Isabelle Guyon, dan Vladimir Vapnik mengusulkan cara untuk membuat klasifikasi non-linear dengan menerapkan trik kernel pada hiperplan margin maksimum. Versi "marginal lembut", seperti yang umum digunakan dalam paket perangkat lunak, diusulkan oleh Corinna Cortes dan Vapnik pada tahun 1993 dan diterbitkan pada tahun 1995.
Implementasi
Parameter dari hiperplan margin maksimum diperoleh dengan memecahkan optimasi. Ada beberapa algoritma khusus untuk dengan cepat memecahkan masalah pemrograman kuadrat (QP) yang muncul dari SVM, sebagian besar mengandalkan heuristik untuk memecah masalah menjadi bagian-bagian yang lebih kecil dan lebih mudah dikelola.
Pendekatan lain adalah menggunakan metode titik dalam yang menggunakan iterasi mirip Newton untuk menemukan solusi dari kondisi Karush–Kuhn–Tucker dari masalah primer dan dual. Alih-alih memecahkan rangkaian masalah yang dipecahkan, pendekatan ini langsung memecahkan masalah secara keseluruhan. Untuk menghindari memecahkan sistem linear yang melibatkan matriks kernel besar, pendekatan ini sering menggunakan aproksimasi peringkat rendah untuk matriks dalam trik kernel.
Metode umum lainnya adalah algoritma optimasi minimal sekuen Platt (SMO), yang memecah masalah menjadi sub-masalah 2 dimensi yang dipecahkan secara analitis, menghilangkan kebutuhan akan algoritma optimasi numerik dan penyimpanan matriks. Algoritma ini secara konseptual sederhana, mudah diimplementasikan, umumnya lebih cepat, dan memiliki sifat scaling yang lebih baik untuk masalah SVM yang sulit.
Kasus khusus dari mesin pendukung vektor linier dapat dipecahkan secara lebih efisien dengan jenis algoritma yang sama yang digunakan untuk mengoptimalkan kerabat dekatnya, regresi logistik; kelas algoritma ini termasuk gradien sub-descent (misalnya, PEGASOS) dan desent koordinat (misalnya, LIBLINEAR). LIBLINEAR memiliki beberapa sifat menarik saat pelatihan. Setiap iterasi konvergensi membutuhkan waktu linear dalam waktu yang dibutuhkan untuk membaca data latih, dan iterasi juga memiliki sifat konvergensi Q-linear, membuat algoritma sangat cepat.
SVM kernel umum juga dapat dipecahkan secara lebih efisien menggunakan gradien sub-descent (misalnya, P-packSVM), terutama ketika paralelisasi diizinkan.
SVM kernel tersedia dalam banyak toolkit pembelajaran mesin, termasuk LIBSVM, MATLAB, SAS, SVMlight, kernlab, scikit-learn, Shogun, Weka, Shark, JKernelMachines, OpenCV, dan lainnya.
Pra-pemrosesan data (standarisasi) sangat dianjurkan untuk meningkatkan akurasi klasifikasi. Ada beberapa metode standarisasi, seperti min-max, normalisasi dengan skala desimal, Z-score. Pengurangan rata-rata dan pembagian dengan varians setiap fitur biasanya digunakan untuk SVM.
Disadur dari: en.wikipedia.org/wiki/Support_vector_machine

Teknik Industri
Analisis Klaster: Mengelompokkan Data untuk Temuan Informasi
Dipublikasikan oleh Sirattul Istid'raj pada 29 April 2025
Analisis klaster atau clustering adalah tugas untuk mengelompokkan serangkaian objek sedemikian rupa sehingga objek dalam kelompok yang sama (yang disebut klaster) lebih mirip (dalam suatu arti tertentu yang ditentukan oleh analis) satu sama lain daripada dengan yang lain. Ini adalah tugas utama dalam analisis data eksploratori, dan merupakan teknik umum untuk analisis data statistik, digunakan dalam banyak bidang, termasuk pengenalan pola, analisis gambar, pengambilan informasi, bioinformatika, kompresi data, grafika komputer, dan pembelajaran mesin.
Analisis klaster merujuk pada keluarga algoritma dan tugas daripada satu algoritma spesifik. Ini dapat dicapai dengan berbagai algoritma yang berbeda secara signifikan dalam pemahaman mereka tentang apa yang merupakan sebuah klaster dan bagaimana cara menemukannya dengan efisien. Pandangan populer tentang klaster termasuk grup dengan jarak kecil antara anggota klaster, area padat di ruang data, interval, atau distribusi statistik tertentu. Oleh karena itu, pengelompokan dapat dirumuskan sebagai masalah optimasi multi-obyektif. Algoritma pengelompokan yang tepat dan pengaturan parameter (termasuk parameter seperti fungsi jarak yang digunakan, ambang batas kepadatan, atau jumlah klaster yang diharapkan) tergantung pada set data individu dan penggunaan yang dimaksudkan dari hasilnya. Analisis klaster sebagai demikian bukanlah tugas otomatis, tetapi merupakan proses iteratif penemuan pengetahuan atau optimasi multi-obyektif interaktif yang melibatkan percobaan dan kegagalan. Seringkali diperlukan untuk memodifikasi pra-pemrosesan data dan parameter model hingga hasil mencapai properti yang diinginkan.
Selain istilah pengelompokan, ada sejumlah istilah dengan makna yang serupa, termasuk klasifikasi otomatis, taksonomi numerik, botryology (dari bahasa Yunani βότρυς "anggur"), analisis tipe, dan deteksi komunitas. Perbedaan halus seringkali terletak pada penggunaan hasil: sementara dalam penambangan data, kelompok yang dihasilkan menjadi pokok perhatian, dalam klasifikasi otomatis, kekuatan diskriminatif yang dihasilkan menjadi pokok perhatian.
Analisis klaster berasal dari antropologi oleh Driver dan Kroeber pada tahun 1932 dan diperkenalkan ke dalam psikologi oleh Joseph Zubin pada tahun 1938 dan Robert Tryon pada tahun 1939, serta digunakan secara terkenal oleh Cattell mulai tahun 1943 untuk klasifikasi teori ciri dalam psikologi kepribadian.
Algoritma Klaster
Ketika berurusan dengan data, salah satu tugas utama adalah mengelompokkan informasi menjadi kelompok yang bermakna. Hal ini memungkinkan kita untuk menemukan pola, mencari kesamaan, dan mendapatkan wawasan yang berharga. Dalam dunia analisis data, ada banyak algoritma yang digunakan untuk melakukan tugas ini, dan masing-masing memiliki pendekatan yang berbeda. Mari kita lihat beberapa algoritma clustering yang paling populer:
1. Hierarchical Clustering: Algoritma ini berdasarkan pada konsep bahwa objek cenderung lebih terkait dengan objek yang berdekatan daripada dengan objek yang jauh. Algoritma ini menghubungkan objek untuk membentuk klaster berdasarkan jarak mereka. Klaster dapat dijelaskan oleh jarak maksimum yang diperlukan untuk menghubungkan bagian dari klaster tersebut. Klaster ini dapat direpresentasikan dengan menggunakan dendrogram, yang menjelaskan mengapa algoritma ini dikenal sebagai hierarchical clustering.
2. K-Means Clustering: Dalam pendekatan ini, setiap klaster direpresentasikan oleh sebuah vektor pusat. Tujuan dari algoritma ini adalah untuk menemukan pusat klaster dan menetapkan objek ke klaster terdekat, sehingga jarak kuadrat dari klaster diminimalkan. Algoritma ini umumnya menggunakan pendekatan pencarian solusi yang lebih cepat, meskipun hanya menemukan optimum lokal.
3. Fuzzy C-Means: Algoritma ini adalah variasi dari k-means yang memungkinkan untuk penugasan klaster yang lebih fleksibel. Sebagai lawan dari klaster yang keras, di mana setiap objek hanya boleh menjadi bagian dari satu klaster, algoritma ini memungkinkan objek untuk menjadi bagian dari setiap klaster dengan tingkat keanggotaan tertentu.
Setiap algoritma ini memiliki keunggulan dan kelemahan tersendiri, dan pilihan terbaik tergantung pada sifat data dan tujuan analisis. Dengan memahami berbagai pendekatan clustering yang tersedia, Anda dapat membuat keputusan yang lebih baik dalam menganalisis dan memahami data Anda.
Model-based clustering menggunakan pendekatan distribusi probabilitas untuk mengelompokkan data ke dalam campuran distribusi probabilitas. Salah satu metode yang umum digunakan adalah Gaussian mixture models (GMM) yang menggunakan algoritma expectation-maximization. Namun, metode ini rentan terhadap overfitting dan sulit untuk memilih kompleksitas model yang tepat.
Clustering berbasis densitas mengidentifikasi klaster sebagai area dengan kepadatan yang lebih tinggi daripada area lain dalam data set. DBSCAN adalah metode clustering berbasis densitas yang populer, tetapi sering menghasilkan batas klaster yang sewenang-wenang pada data dengan distribusi Gauss tumpang tindih. Mean-shift adalah pendekatan clustering lain yang memindahkan setiap objek ke area padat terdekat dalam data.
Pengembangan terbaru dalam clustering termasuk peningkatan kinerja algoritma yang ada dan pengembangan metode untuk data berdimensi tinggi. Salah satu pendekatan yang digunakan adalah clustering subspace dan clustering korelasi, yang mencari klaster dalam ruang subspace atau berdasarkan korelasi atributnya. Beberapa sistem clustering juga berdasarkan informasi saling mendukung, seperti metrik variasi informasi Marina Meilā dan algoritma genetika untuk optimasi fungsi-fit.
Evaluasi dan Penilaian Custering
Evaluasi hasil clustering merupakan tantangan yang sama sulitnya dengan proses clustering itu sendiri. Pendekatan populer melibatkan evaluasi "internal", "eksternal", "manual" oleh pakar manusia, dan "tidak langsung" dengan mengevaluasi kegunaan clustering dalam aplikasinya yang dimaksud.
Pengukuran evaluasi internal cenderung mewakili fungsi yang dapat dilihat sebagai tujuan clustering itu sendiri. Evaluasi eksternal memiliki masalah serupa: jika kita memiliki label "kebenaran dasar" maka kita tidak perlu melakukan clustering; dan dalam aplikasi praktis, kita biasanya tidak memiliki label semacam itu. Tidak ada pendekatan yang dapat sepenuhnya menilai kualitas sebenarnya dari suatu clustering, namun evaluasi manusia dapat memberikan kontribusi yang berharga, meskipun subjektif.
Meskipun demikian, statistik seperti ini dapat memberikan wawasan yang bermanfaat dalam mengidentifikasi clustering yang buruk, namun evaluasi manusia juga penting untuk dipertimbangkan.
Disadur dari: en.wikipedia.org/wiki/Cluster_analysis

Teknik Industri
Menjelajahi Pengurangan Dimensi: Menyederhanakan Analisis Data untuk Wawasan yang Lebih Baik
Dipublikasikan oleh Sirattul Istid'raj pada 29 April 2025
Reduksi dimensi, atau juga dikenal sebagai pengurangan dimensi, adalah proses mengubah data dari ruang berdimensi tinggi menjadi ruang berdimensi rendah sehingga representasi berdimensi rendah tersebut tetap mempertahankan beberapa properti penting dari data asli, idealnya mendekati dimensi intrinsiknya. Bekerja dalam ruang berdimensi tinggi dapat tidak diinginkan karena berbagai alasan; data mentah seringkali bersifat langka sebagai akibat dari kutukan dimensi, dan menganalisis data tersebut biasanya sulit secara komputasi.
Pengurangan dimensi umum dalam bidang yang berurusan dengan banyak pengamatan dan/atau banyak variabel, seperti pengolahan sinyal, pengenalan ucapan, neuroinformatika, dan bioinformatika.
Metode umumnya dibagi menjadi pendekatan linear dan non-linear. Pendekatan juga dapat dibagi menjadi seleksi fitur dan ekstraksi fitur. Pengurangan dimensi dapat digunakan untuk pengurangan noise, visualisasi data, analisis cluster, atau sebagai langkah intermediet untuk memfasilitasi analisis lainnya.
-
Pendekatan seleksi fitur bertujuan untuk menemukan subset dari variabel input. Tiga strategi utamanya adalah:
- Strategi Filter: Misalnya menggunakan keuntungan informasi untuk memilih fitur.
- Strategi Pembungkus: Misalnya melakukan pencarian yang dipandu oleh akurasi.
- Strategi Tertanam: Fitur yang dipilih ditambahkan atau dihapus saat membangun model berdasarkan kesalahan prediksi.
-
Analisis data seperti regresi atau klasifikasi sering dilakukan di ruang yang direduksi, karena ini dapat lebih akurat daripada di ruang asli.
-
Feature projection atau ekstraksi fitur adalah proses mentransformasi data dari ruang berdimensi tinggi menjadi ruang berdimensi lebih rendah. Ini penting untuk mengatasi masalah yang melibatkan data dengan dimensi tinggi seperti analisis citra, pengenalan pola, dan pemrosesan sinyal.
-
Principal Component Analysis (PCA) adalah salah satu teknik utama dalam feature projection. PCA melakukan pemetaan linear dari data ke ruang berdimensi lebih rendah sehingga variansi data dalam representasi berdimensi rendah maksimal.
-
Non-negative Matrix Factorization (NMF) adalah teknik nonlinear yang memecah matriks non-negatif menjadi hasil perkalian dua matriks non-negatif. Ini berguna di bidang-bidang di mana sinyal hanya ada dalam bentuk non-negatif, seperti astronomi.
-
Kernel PCA memungkinkan konstruksi pemetaan nonlinear dengan memanfaatkan trik kernel. Sedangkan, manifold learning seperti Isomap dan Locally Linear Embedding (LLE) membangun representasi data berdimensi rendah dengan mempertahankan properti lokal data.
-
Autoencoder adalah pendekatan lain yang menggunakan jaringan saraf tiruan khusus untuk pembelajaran representasi data berdimensi rendah.
-
Untuk visualisasi data berdimensi tinggi, teknik seperti t-distributed Stochastic Neighbor Embedding (t-SNE) dan Uniform Manifold Approximation and Projection (UMAP) sering digunakan. Meskipun berguna untuk visualisasi, t-SNE tidak disarankan untuk analisis seperti pengelompokan atau deteksi outlier karena tidak selalu mempertahankan densitas atau jarak dengan baik.
Dengan berbagai teknik ini, feature projection memberikan alat yang kuat untuk mengatasi kompleksitas data berdimensi tinggi dan memperoleh pemahaman yang lebih baik tentang struktur data.
Pengurangan Dimensi
Untuk dataset berdimensi tinggi (yaitu dengan jumlah dimensi lebih dari 10), seringkali dilakukan reduksi dimensi sebelum menerapkan algoritma K-nearest neighbors (k-NN) untuk menghindari efek dari kutukan dimensi.
Ekstraksi fitur dan reduksi dimensi dapat digabungkan dalam satu langkah menggunakan teknik seperti principal component analysis (PCA), linear discriminant analysis (LDA), canonical correlation analysis (CCA), atau non-negative matrix factorization (NMF) sebagai langkah pra-pemrosesan yang diikuti dengan pengelompokan oleh k-NN pada vektor fitur dalam ruang dimensi yang direduksi. Dalam pembelajaran mesin, proses ini juga disebut sebagai penanaman dimensi rendah.
Untuk dataset yang sangat berdimensi tinggi (misalnya saat melakukan pencarian kesamaan pada aliran video langsung, data DNA, atau deret waktu berdimensi tinggi), menjalankan pencarian k-NN perkiraan cepat menggunakan hashing sensitivitas lokal, proyeksi acak, "sketsa", atau teknik pencarian kesamaan berdimensi tinggi lainnya dari toolbox konferensi VLDB mungkin merupakan satu-satunya opsi yang memungkinkan.
Aplikasi
Teknik reduksi dimensi yang kadang-kadang digunakan dalam neurosains adalah dimensi maksimal yang informatif, yang menemukan representasi dimensi yang lebih rendah dari sebuah dataset sehingga sebanyak mungkin informasi tentang data asli tetap dipertahankan.
Disadur dari: en.wikipedia.org/wiki/Dimensionality_reduction

Teknik Industri
Keajaiban Sederhana Naive Bayes: Menyederhanakan Klasifikasi dengan Efektivitas Tinggi
Dipublikasikan oleh Sirattul Istid'raj pada 29 April 2025
Naive Bayes, meskipun sederhana dalam desainnya, memiliki keajaiban tersendiri dalam dunia klasifikasi statistik. Ini adalah keluarga "klasifier probabilistik" yang mengasumsikan independensi kondisional antara fitur-fitur yang ada, dengan asumsi target kelas. Kekuatan dari asumsi "naif" ini adalah apa yang memberikan nama pada klasifier ini. Naive Bayes adalah salah satu model jaringan Bayesian yang paling sederhana.
Salah satu kelebihan besar dari Naive Bayes adalah skalabilitasnya yang tinggi. Ini membutuhkan jumlah parameter yang linear terhadap jumlah variabel (fitur/predictor) dalam sebuah masalah pembelajaran. Pelatihan maximum-likelihood bisa dilakukan dengan mengevaluasi ekspresi bentuk tertutup, yang membutuhkan waktu linear, bukan dengan pendekatan iteratif yang mahal seperti yang digunakan untuk banyak jenis klasifier lainnya.
Di literatur statistik, model Naive Bayes dikenal dengan berbagai nama, termasuk Bayes sederhana dan independensi Bayes. Semua nama ini mengacu pada penggunaan teorema Bayes dalam aturan keputusan klasifier, namun Naive Bayes tidak (secara mutlak) merupakan metode Bayesian.
Naive Bayes adalah teknik sederhana untuk membangun klasifier: model yang memberikan label kelas kepada instansi masalah, direpresentasikan sebagai vektor nilai fitur, di mana label kelas diambil dari sekumpulan terbatas. Tidak ada satu algoritma tunggal untuk melatih klasifier semacam itu, tetapi sekelompok algoritma berdasarkan prinsip umum: semua klasifier Naive Bayes mengasumsikan bahwa nilai dari suatu fitur tertentu independen dari nilai fitur lainnya, mengingat variabel kelas. Misalnya, sebuah buah mungkin dianggap sebagai apel jika berwarna merah, bulat, dan memiliki diameter sekitar 10 cm. Klasifier Naive Bayes mempertimbangkan setiap fitur ini untuk memberikan kontribusi secara independen terhadap probabilitas bahwa buah ini adalah apel, tanpa memperhatikan korelasi yang mungkin antara warna, kebulatan, dan diameter fitur-fitur tersebut.
Di banyak aplikasi praktis, estimasi parameter untuk model Naive Bayes menggunakan metode maximum likelihood; dengan kata lain, seseorang dapat bekerja dengan model Naive Bayes tanpa menerima probabilitas Bayesian atau menggunakan metode Bayesian apa pun.
Meskipun desainnya yang naif dan asumsi yang tampaknya terlalu disederhanakan, klasifier Naive Bayes telah berhasil dalam banyak situasi dunia nyata yang kompleks. Pada tahun 2004, analisis terhadap masalah klasifikasi Bayesian menunjukkan bahwa ada alasan teoritis yang kuat untuk keefektifan tampaknya yang luar biasa dari klasifier Naive Bayes. Namun, perbandingan komprehensif dengan algoritma klasifikasi lain pada tahun 2006 menunjukkan bahwa klasifikasi Bayes kalah oleh pendekatan lain, seperti pohon yang diperkuat atau hutan acak.
Salah satu keunggulan dari Naive Bayes adalah bahwa ia hanya memerlukan sedikit data pelatihan untuk mengestimasi parameter yang diperlukan untuk klasifikasi.
Model Probabilistik
Secara abstrak, Naive Bayes adalah model probabilitas bersyarat: model ini memberikan probabilitas 


Masalah dengan rumusan di atas adalah jika jumlah fitur n besar atau jika suatu fitur dapat mempunyai nilai yang banyak, maka mendasarkan model seperti itu pada tabel probabilitas tidak mungkin dilakukan. Oleh karena itu, model tersebut harus diformulasi ulang agar lebih mudah diterapkan. Dengan menggunakan teorema Bayes, probabilitas bersyarat dapat diuraikan menjadi:

Dalam bahasa Inggris sederhana, dengan menggunakan terminologi probabilitas Bayesian, persamaan di atas dapat ditulis sebagai

Dalam prakteknya, yang menarik hanya pada pembilang pecahan tersebut, karena penyebutnya tidak bergantung pada 

Ini dapat diulas kembali dengan menggunakan aturan rantai untuk aplikasi berulang dari definisi probabilitas kondisional:

Kini asumsi independensi bersyarat yang "naif" mulai berlaku: asumsikan bahwa semua fitur ada di dalamnya 

Dengan demikian, model gabungan dapat dinyatakan sebagai

dimana ∝ menunjukkan proporsionalitas sejak penyebutnya 
Artinya berdasarkan asumsi independensi di atas, distribusi bersyarat atas variabel kelas

dengan bukti 
Membangun pengklasifikasi dari model probabilitas
Membangun pengklasifikasi dari model probabilitas melibatkan pengintegrasian model fitur independen turunan, yaitu model probabilitas naif Bayes, dengan aturan keputusan. Pendekatan yang umum adalah memilih hipotesis dengan probabilitas tertinggi untuk meminimalkan kesalahan klasifikasi, yang dikenal sebagai aturan keputusan maksimum a posteriori atau MAP. Pengklasifikasi yang sesuai, pengklasifikasi Bayes, menentukan label kelas 

Formulasi ini mencari label kelas yang memaksimalkan produk probabilitas sebelumnya dari kelas tersebut dan probabilitas bersyarat dari fitur-fitur yang diberikan pada kelas tersebut.
Teori dan Praktik Naive Bayes Klasifikasi
Naive Bayes adalah algoritma klasifikasi yang telah terbukti efektif dalam berbagai aplikasi, mulai dari filter spam hingga klasifikasi dokumen. Namun, untuk memahami bagaimana algoritma ini bekerja, penting untuk memahami konsep dasarnya.
Pertama-tama, Naive Bayes adalah model probabilitas yang bersifat kondisional. Ini berarti bahwa algoritma ini menilai probabilitas untuk setiap kelas berdasarkan pada nilai-nilai fitur yang diamati. Untuk membangun klasifier dari model probabilitas ini, kita memadukan model tersebut dengan aturan keputusan. Salah satu aturan umum adalah aturan keputusan MAP (Maximum a Posteriori), di mana kita memilih hipotesis yang paling mungkin untuk meminimalkan probabilitas kesalahan klasifikasi.
Untuk menghitung probabilitas prior sebuah kelas, kita dapat menggunakan pendekatan sederhana dengan menganggap kelas-kelas memiliki probabilitas yang sama (equiprobable), atau kita bisa menghitung perkiraan probabilitas kelas dari set data pelatihan. Selanjutnya, untuk mengestimasi parameter untuk distribusi fitur, kita harus mengasumsikan suatu distribusi atau membuat model nonparametrik dari fitur-fitur berdasarkan pada set data pelatihan.
Ada dua model peristiwa (event models) yang umum digunakan dalam Naive Bayes: model Gauss dan model multinomial. Model Gauss digunakan untuk data kontinu, sementara model multinomial cocok untuk data diskrit seperti yang ditemui dalam klasifikasi dokumen.
Model Gauss mengasumsikan bahwa nilai-nilai kontinu yang terkait dengan setiap kelas didistribusikan secara normal. Di sisi lain, model multinomial menganggap sampel sebagai frekuensi munculnya suatu peristiwa yang dihasilkan oleh suatu distribusi multinomial. Model Bernoulli, bagaimanapun, merupakan pilihan yang baik untuk data biner atau Boolean, seperti yang sering terjadi dalam klasifikasi dokumen.
Dalam prakteknya, Naive Bayes dapat diaplikasikan secara luas. Dengan menggunakan teknik semi-supervised learning, kita bahkan dapat meningkatkan kinerja klasifikasi dengan memanfaatkan data yang tidak berlabel. Ini memungkinkan kita untuk mengoptimalkan model kita bahkan ketika sumber daya yang tersedia terbatas.
Naive Bayes telah terbukti sebagai algoritma yang kuat dan efisien dalam klasifikasi, terutama dalam situasi di mana data terbatas. Dengan pemahaman yang tepat tentang konsep dasarnya dan penerapan teknik yang sesuai, kita dapat memanfaatkan kekuatan algoritma ini dalam berbagai konteks aplikasi.
Keunggulan Naive Bayes: Meskipun Naif, Tetap Efektif
Meskipun Naive Bayes mengandalkan asumsi independensi yang sering kali tidak akurat, klasifier ini memiliki beberapa sifat yang membuatnya sangat berguna dalam praktik. Salah satunya adalah pemisahan distribusi fitur kondisional kelas yang memungkinkan setiap distribusi untuk diestimasi secara independen sebagai distribusi satu dimensi. Ini membantu mengurangi masalah yang timbul dari "kutukan dimensi", seperti kebutuhan akan set data yang berkembang secara eksponensial dengan jumlah fitur.
Meskipun Naive Bayes sering kali gagal menghasilkan perkiraan yang baik untuk probabilitas kelas yang benar, hal ini mungkin tidak menjadi keharusan untuk banyak aplikasi. Misalnya, klasifier Naive Bayes akan membuat keputusan klasifikasi aturan MAP yang benar selama kelas yang benar diprediksi sebagai lebih mungkin daripada kelas lainnya. Hal ini berlaku terlepas dari apakah perkiraan probabilitas sedikit atau bahkan sangat tidak akurat. Dengan cara ini, klasifier secara keseluruhan dapat cukup tangguh untuk mengabaikan kekurangan serius dalam model probabilitas naif yang mendasarinya.
Disadur dari: en.wikipedia.org/wiki/Naive_Bayes_classifier

Teknik Industri
Panduan Singkat tentang Klasifikasi Statistik: Jenis, Algoritma, dan Evaluasi
Dipublikasikan oleh Sirattul Istid'raj pada 29 April 2025
Dalam statistik, klasifikasi adalah sebuah masalah yang mencoba untuk mengidentifikasi ke dalam salah satu dari beberapa kategori (sub-populasi) sebuah observasi. Contohnya adalah menentukan apakah sebuah email tertentu masuk ke dalam kelas "spam" atau "non-spam", atau menentukan diagnosis untuk seorang pasien berdasarkan karakteristik yang diamati dari pasien tersebut (seperti jenis kelamin, tekanan darah, atau kehadiran atau ketiadaan gejala tertentu).
Observasi-individu sering kali dianalisis menjadi serangkaian properti yang dapat diukur, yang dikenal dengan berbagai istilah seperti variabel penjelas atau fitur. Properti-properti ini bisa berupa kategori, ordinal, bernilai-integer, atau bernilai-real. Klasifikasi juga dapat dilakukan dengan membandingkan observasi dengan observasi sebelumnya melalui fungsi kesamaan atau jarak.
Sebuah algoritma yang mengimplementasikan klasifikasi, terutama dalam implementasi konkretnya, dikenal sebagai klasifier. Istilah "klasifier" kadang juga mengacu pada fungsi matematika, yang diimplementasikan oleh algoritma klasifikasi, yang memetakan data masukan ke dalam kategori.
Terminologi di berbagai bidang cukup beragam. Dalam statistik, di mana klasifikasi sering dilakukan dengan regresi logistik atau prosedur serupa, properti observasi disebut variabel penjelas (atau variabel independen, regressor, dll.), dan kategori yang akan diprediksi disebut sebagai hasil, yang dianggap sebagai nilai-nilai yang mungkin dari variabel dependen. Di machine learning, observasi sering disebut sebagai instance, variabel penjelas disebut fitur (dikelompokkan ke dalam vektor fitur), dan kategori yang mungkin diprediksi disebut sebagai kelas. Bidang lain mungkin menggunakan terminologi yang berbeda: misalnya, dalam ekologi komunitas, istilah "klasifikasi" biasanya mengacu pada analisis klaster.
Klasifikasi dan pengelompokan adalah contoh dari masalah pengenalan pola yang lebih umum, yang merupakan penugasan nilai keluaran tertentu kepada nilai masukan yang diberikan. Contoh lainnya adalah regresi, yang menugaskan nilai nyata ke setiap masukan; penandaan urutan, yang menetapkan kelas ke setiap anggota dari sebuah urutan nilai (misalnya, penandaan bagian pidato, yang menetapkan bagian pidato untuk setiap kata dalam sebuah kalimat masukan); pengurai, yang menetapkan sebuah pohon pengurai ke sebuah kalimat masukan, yang menggambarkan struktur sintaksis dari kalimat tersebut; dll.
Hubungan Dengan Masalah Lain
Sebuah subkelas umum dari klasifikasi adalah klasifikasi probabilistik. Algoritma-algoritma jenis ini menggunakan inferensi statistik untuk menemukan kelas terbaik untuk sebuah instance tertentu. Berbeda dengan algoritma-algoritma lain, yang hanya menghasilkan kelas "terbaik", algoritma probabilistik menghasilkan probabilitas dari instance tersebut menjadi anggota dari setiap kelas yang mungkin. Kelas terbaik biasanya dipilih sebagai kelas dengan probabilitas tertinggi. Namun, algoritma semacam ini memiliki banyak keunggulan dibandingkan dengan klasifier non-probabilistik:
- Dapat menghasilkan nilai kepercayaan yang terkait dengan pilihannya (secara umum, klasifier yang dapat melakukan ini dikenal sebagai klasifier yang memperhitungkan kepercayaan).
- Sebagai respons, dapat menahan diri saat kepercayaannya dalam memilih keluaran tertentu terlalu rendah.
- Karena probabilitas yang dihasilkan, klasifier probabilistik dapat lebih efektif dimasukkan ke dalam tugas-tugas pembelajaran mesin yang lebih besar, dengan cara yang sebagian atau sepenuhnya menghindari masalah penyebaran kesalahan.
Prosedur Yang Sering Dilakukan
Pada awalnya, pekerjaan awal tentang klasifikasi statistik dilakukan oleh Fisher dalam konteks masalah dua kelompok, yang menghasilkan fungsi diskriminan linear Fisher sebagai aturan untuk menetapkan kelompok pada sebuah observasi baru. Pekerjaan awal ini mengasumsikan bahwa nilai data dalam setiap dari dua kelompok memiliki distribusi multivariat normal. Perluasan dari konteks yang sama ini ke lebih dari dua kelompok juga telah dipertimbangkan dengan diberlakukannya batasan bahwa aturan klasifikasi harus linear. Kemudian, pekerjaan untuk distribusi normal multivariat memungkinkan klasifier menjadi non-linear: beberapa aturan klasifikasi dapat diperoleh berdasarkan penyesuaian berbeda dari jarak Mahalanobis, dengan sebuah observasi baru ditugaskan ke kelompok yang pusatnya memiliki jarak terbesar yang disesuaikan dari observasi tersebut.
Prosedur Bayesian
Prosedur Bayesian, berbeda dengan prosedur Frequentist, menyediakan cara alami untuk memperhitungkan informasi yang tersedia tentang ukuran relatif dari berbagai kelompok dalam populasi secara keseluruhan. Prosedur Bayesian cenderung mahal secara komputasi dan, pada masa sebelum komputasi rantai Markov Monte Carlo dikembangkan, aproksimasi untuk aturan pengelompokan Bayesian diperkirakan. Beberapa prosedur Bayesian melibatkan perhitungan probabilitas keanggotaan kelompok: ini memberikan hasil yang lebih informatif daripada atribusi sederhana dari sebuah label kelompok kepada setiap observasi baru.
Klasifikasi Biner Dan Multikelas
Klasifikasi dapat dipikirkan sebagai dua masalah terpisah - klasifikasi biner dan klasifikasi multikelas. Dalam klasifikasi biner, tugas yang lebih dipahami, hanya ada dua kelas yang terlibat, sedangkan klasifikasi multikelas melibatkan penugasan objek ke salah satu dari beberapa kelas. Karena banyak metode klasifikasi telah dikembangkan khusus untuk klasifikasi biner, klasifikasi multikelas seringkali membutuhkan penggunaan gabungan dari beberapa klasifier biner.
Vektor Fitur
Fitur vektor digunakan untuk menggambarkan instance yang kategori-nya akan diprediksi menggunakan serangkaian properti yang dapat diukur dari instance tersebut. Setiap properti disebut fitur, juga dikenal dalam statistik sebagai variabel penjelas (atau variabel independen, meskipun fitur mungkin atau mungkin tidak independen secara statistik). Fitur dapat berupa biner, kategorikal, ordinal, bernilai-integer, atau bernilai-real. Jika instance adalah gambar, nilai fitur mungkin sesuai dengan piksel gambar; jika instance adalah potongan teks, nilai fitur mungkin adalah frekuensi kemunculan kata-kata yang berbeda. Beberapa algoritma hanya bekerja dalam hal data diskrit dan memerlukan bahwa data bernilai-real atau bernilai-integer diskritisasi menjadi kelompok-kelompok.
Classifier algoritma sering kali dibentuk sebagai sebuah fungsi linear yang menetapkan skor untuk setiap kategori mungkin dengan menggabungkan vektor fitur dari sebuah instance dengan sebuah vektor bobot, menggunakan perkalian titik. Kategori yang diprediksi adalah kategori dengan skor tertinggi. Fungsi skor semacam ini dikenal sebagai fungsi prediktor linear dan memiliki bentuk umum berikut:

Di mana Xi adalah vektor fitur untuk instance i, βk adalah vektor bobot yang sesuai dengan kategori k, dan score (Xi,k) adalah skor yang terkait dengan menugaskan instance i ke kategori k. Dalam teori pilihan diskrit, di mana instance mewakili orang dan kategori mewakili pilihan, skor tersebut dianggap sebagai utilitas yang terkait dengan orang i memilih kategori k.
Algoritma Klasifikasi Statistik
Algoritma dengan setup dasar ini dikenal sebagai klasifier linear. Yang membedakan mereka adalah prosedur untuk menentukan (pelatihan) bobot/koefisien optimal dan cara interpretasi skor tersebut.
Contoh algoritma semacam ini termasuk:
- Regresi logistik – Model statistik untuk variabel dependen biner
- Regresi logistik multinomial – Regresi untuk lebih dari dua hasil diskrit
- Regresi Probit – Regresi statistik di mana variabel dependen hanya dapat mengambil dua nilai
- Algoritma perceptron
- Mesin vektor pendukung – Set metode untuk pembelajaran statistik terawasi
- Analisis diskriminan linear – Metode yang digunakan dalam statistik, pengenalan pola, dan bidang lainnya
Karena tidak ada bentuk tunggal klasifikasi yang sesuai untuk semua set data, telah dikembangkan berbagai algoritma klasifikasi. Yang paling umum digunakan meliputi:
- Jaringan syaraf tiruan – Model komputasi yang digunakan dalam pembelajaran mesin, berdasarkan fungsi terhubung dan hierarkis
- Peningkatan (meta-algoritma) – Metode dalam pembelajaran mesin
- Pembelajaran pohon keputusan – Algoritma pembelajaran mesin
- Hutan acak – Metode pembelajaran mesin berbasis pohon pencarian biner
- Pemrograman genetika – Evolusi program komputer dengan teknik analogi proses genetik alami
- Pemrograman ekspresi gen – Algoritma evolusioner
- Pemrograman ekspresi multi
- Pemrograman genetika linier – jenis algoritma pemrograman genetika
- Estimasi kernel – Fungsi jendela
- k-tetangga terdekat – Metode klasifikasi non-parametrik
- Quantization vektor pembelajaran
- Klasifikasi linear – Klasifikasi statistik dalam pembelajaran mesin
- Analisis diskriminan linear Fisher – Metode yang digunakan dalam statistik, pengenalan pola, dan bidang lainnya
- Regresi logistik – Model statistik untuk variabel dependen biner
- Klasifier Naive Bayes – Algoritma klasifikasi probabilistik
- Perceptron – Algoritma untuk pembelajaran terawasi klasifikasi biner
- Klasifikasi kuadrat – digunakan dalam pembelajaran mesin untuk memisahkan pengukuran dari dua atau lebih kelas objek
- Mesin vektor pendukung – Set metode untuk pembelajaran statistik terawasi
- Mesin vektor pendukung kuadrat terkecil
Evaluasi
Kinerja klasifier sangat bergantung pada karakteristik data yang akan diklasifikasikan. Tidak ada klasifier tunggal yang terbaik untuk semua masalah yang diberikan (fenomena yang mungkin dijelaskan oleh teorema tidak ada makan siang gratis). Berbagai uji empiris telah dilakukan untuk membandingkan kinerja klasifier dan untuk menemukan karakteristik data yang menentukan kinerja klasifier. Menentukan klasifier yang sesuai untuk masalah tertentu masih lebih merupakan seni daripada ilmu.
Ukurannya presisi dan recall adalah metrik populer yang digunakan untuk mengevaluasi kualitas sistem klasifikasi. Lebih baru-baru ini, kurva receiver operating characteristic (ROC) telah digunakan untuk mengevaluasi pertukaran antara tingkat positif- dan negatif palsu dari algoritma klasifikasi.
Sebagai metrik kinerja, koefisien ketidakpastian memiliki keuntungan atas akurasi sederhana karena tidak dipengaruhi oleh ukuran relatif dari kelas-kelas yang berbeda. Selanjutnya, itu tidak akan menghukum sebuah algoritma hanya karena mengatur ulang kelas-kelas.
Penerapan Domain Aplikasi
erbagai domain memiliki penerapan klasifikasi yang luas. Dalam beberapa kasus, ini digunakan sebagai prosedur penambangan data, sementara dalam yang lain, pemodelan statistik yang lebih rinci dilakukan.
- Klasifikasi biologis – Ilmu yang mengidentifikasi, mendeskripsikan, menentukan, dan memberi nama kelompok organisme biologis.
- Biometrik – Metrik terkait dengan identifikasi karakteristik manusia.
- Visi komputer – Ekstraksi informasi terkomputerisasi dari gambar.
- Analisis citra medis dan pencitraan medis – Teknik dan proses pembuatan representasi visual dari dalam tubuh.
- Pengenalan karakter optik – Pengenalan teks visual oleh komputer.
- Pelacakan video – Menemukan objek dalam setiap frame urutan video.
- Skoring kredit – Ekspresi numerik yang mewakili kelayakan kredit seseorang.
- Klasifikasi dokumen – Proses pengategorian dokumen.
- Penemuan dan pengembangan obat – Proses membawa obat farmasi baru ke pasar.
- Toksigenomika – Cabang toksikologi dan genomika.
- Hubungan struktur-aktivitas kuantitatif – Prediksi kuantitatif aktivitas biologis, ekotoksikologi, atau farmasi dari molekul.
- Geostatistika – Cabang statistik yang berfokus pada kumpulan data spasial.
- Pengenalan tulisan tangan – Kemampuan komputer untuk menerima dan menafsirkan input tulisan tangan yang dapat dimengerti.
- Mesin pencari internet.
- Klasifikasi mikroarray.
- Pengenalan pola – Pengenalan otomatis pola dan keteraturan dalam data.
- Sistem rekomendasi – Sistem penyaringan informasi untuk memprediksi preferensi pengguna.
- Pengenalan ucapan – Konversi otomatis bahasa lisan menjadi teks.
- Pemrosesan bahasa alami statistik – Bidang linguistik dan ilmu komputer.
Disadur dari: en.wikipedia.org
